Explained: DryRun stage
Behaviour
During the DryRun stage, a change is deployed to a separete isolated environment, the purpose of which is to validate the change. The way the change is deployed doesn’t differ from deploying a change to DTAP.
The DryRun stage writes execution logs of the deployment to disk using a git commit. In case the deployment fails, the execution logs include the original execution error returned by the database. After a fix has been made, a new run of the DryRun stage will update the execution logs with a succesful run. The git history will keep track of any previous unsuccesful deployments. An example is shown below:

| In this colored git-update, red lines originate from a previous unsuccesful run followed by green lines originating from a more recent succesful run. |
What does a DryRun validate?
Common mistakes found in the DryRun stage include the following:
-
A change contains a syntax error
-
A change is executed by a role with insufficient privileges
-
A change is dependend on a missing object that is not yet created
-
A change alters multiple files and these files are deployed in the wrong order, causing a dependency error
The DryRun stage is extremely powerfull to detect these errors before an actual deployment. The execution logs help pinpoint these problems quickly. Below are some examples of execution logs containing these errors.
A syntax error is highlighted in RED:

| "CREAT" should be rewritten to "CREATE" in order to have valid Snowflake-syntax |
A missing object error and a insufficient privileges give the same error:
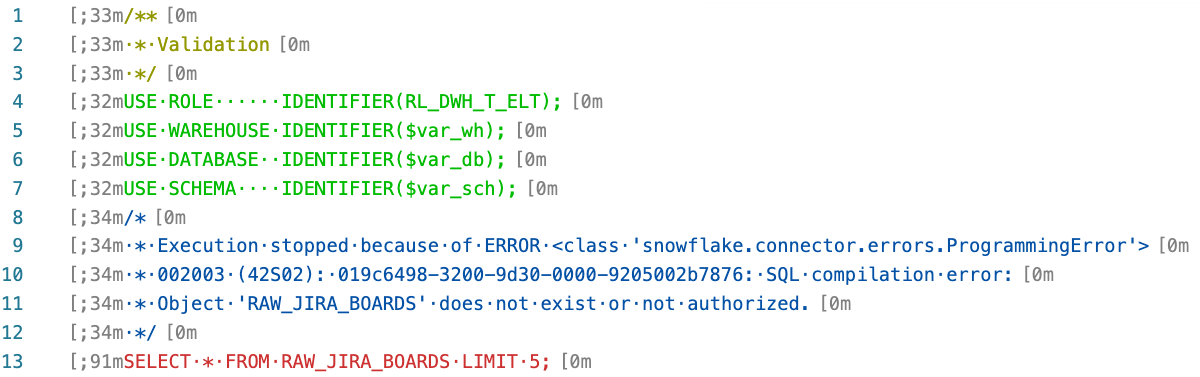
| The error is caused by either the table RAW_JIRA_BOARDS that doesn’t exist OR the role RL_DWH_T_ELT doesn’t have the priviliges to see RAW_JIRA_BOARDS. |
DryRun-environment considerations
In an ideal world, each run of the DryRun stage would instantly create the DryRun-environment from scratch. That way, earlier incorrect deployed changes will not impact new ones in any way. However, in reality, creating an evironment from scratch comes at the high cost of long execution times each time the DryRun stage would run.
Therefore, our advise: do not clean the DryRun environment. Here are our arguments:
-
When developing SQL scripts using the AAA best practices, a mistake in the Assume or Assert step cannot impact the environment. This is because these steps don’t make changes to the environment.
-
Hence, only a mistake in the ACT step can cause a wrong change to be deployed on the DryRun environment.
-
Most changes are deployed with templates. Our templates follow the AAA best practices. Therefore, the previous bullets apply.
-
For the rare occasion that a wrong change would be deployed to the DryRun environment, we advise to grant higher rights to users to this environment in order to fix the problem at hand. From a security point of view, this is safe, because the DryRun environment is isolated. Additionally, they know what they deployed. Worst case, a user makes a terrible mistake in the DryRun-environment. If a manual fix is not easy to make, there is still the option to truncate the environment and recreate it from scratch.
In summary, it is oke for the the DryRun environment to get out of sync with AAA environments. It’s goal is not to reflect these environments, but to act as a safeguard for the previously mentioned types of errors.